
DeepSeek V4发布,最慌的不是OpenAI
@hexo V4发布,最慌的不是OpenAI

**DeepSeek V4发布了。**1.6万亿参数,原生支持100万Token上下文。这已经够炸裂了,但更炸裂的是,同一天,华为跳出来说:我们的昇腾芯片,已经全面支持了。
Day 0适配。不是"正在努力",不是"计划中",是发布当天就跑通了。
我盯着屏幕愣了好几秒。倒不是因为惊讶,而是突然意识到:等了这么久的东西,终于来了。
这款模型到底什么水平
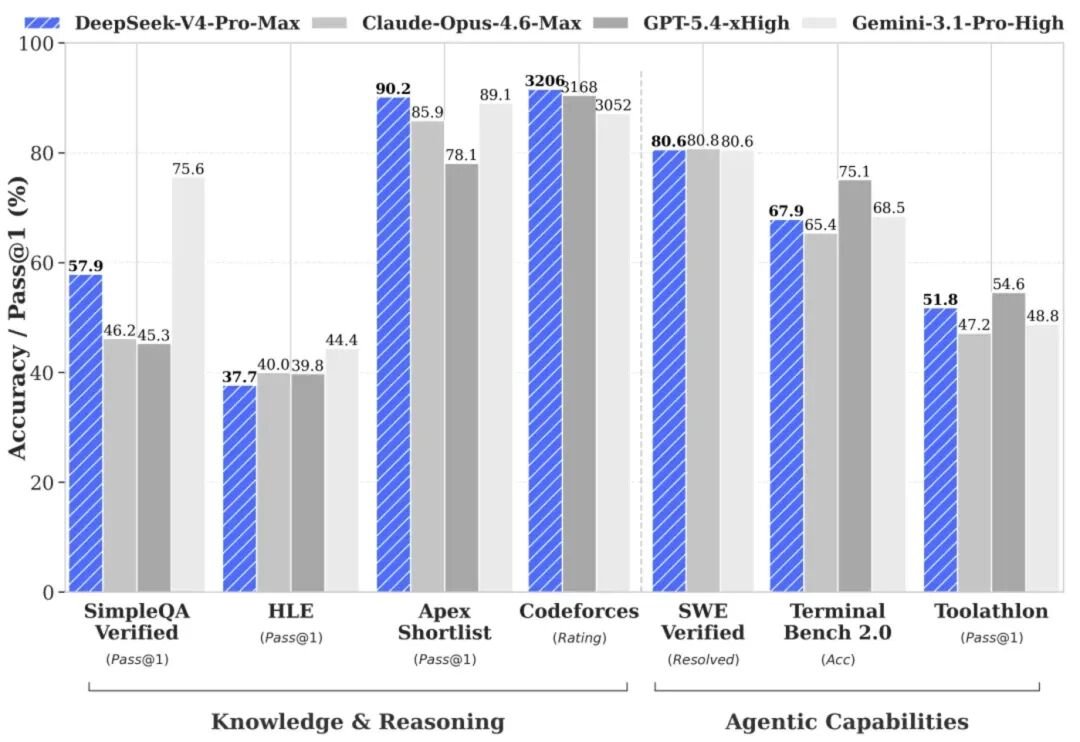
先说参数。V4-Pro,1.6万亿总参数,但每次只激活490亿。这个设计很聪明,就像你开了一家连锁餐厅,不用每家店都塞满厨师,需要的时候再调配人手。
结果是什么呢?它能处理100万Token的上下文。你把整本《红楼梦》扔给它,它不仅能看完,还能帮你分析林黛玉到底爱不爱贾宝玉,顺便画个人物关系图。
更夸张的是它的效率。官方数据:跑100万Token,V4-Pro的推理FLOPs只有前代V3.2的27%,KV缓存占用降到10%。翻译成人话,别人跑这个活儿需要8张卡,它1张就扛得住。
性能定位呢?DeepSeek官方给了个很诚实的说法:比Anthropic的Sonnet 4.5强,接近Opus 4.6的普通模式,但跟GPT-5.4和Gemini-3.1-Pro还有3到6个月的差距。
这种"实话实说"的风格,在AI圈里真的不多见。大部分公司发布会都是"全面超越"“行业领先”,DeepSeek直接告诉你"我们还差半年"。反而让人觉得靠谱。
几个硬核数据:Codeforces评分3206,Terminal Bench 2.0得分67.9%,Toolathlon 51.8%。国产开源大模型里,断层第一,没有之一。

但这些都不是重点
重点是华为。
过去几年,国内做大模型的公司不少,但有个尴尬的现实:训练和推理几乎都绑死在英伟达的芯片上。A100、H100,买都买不到,还被各种出口管制卡脖子。
你模型做得再好,人家不卖你芯片,你就是巧妇难为无米之炊。
所以每次看到"国产大模型突破"的新闻,我心里都打个问号:跑在谁家的卡上?如果是英伟达,那这个"突破"就带着一层隐忧。
但这次不一样。
华为昇腾950超节点,跑V4-Pro,8K输入场景,单卡Decode吞吐4700 TPS,延迟20毫秒。V4-Flash更猛,10毫秒延迟,1600 TPS。

昇腾950 + V4-Pro:TPOT约20ms,单卡4700 TPS
昇腾950 + V4-Flash:TPOT约10ms,单卡1600 TPS
昇腾A3 64卡超节点 + V4-Flash:单卡2000+ TPS
这些数字这说明什么?意味着它真的能用。不是实验室里的演示,是能扛住真实业务流量的生产级性能。
而且华为不是简单地让模型"跑起来"就完事了。他们做了10多种定制的融合算子,专门针对V4的注意力压缩机制做了硬件级适配,连KV缓存的分配管理都重新设计了。
这种级别的软硬件协同,全球能做到的组合屈指可数:OpenAI配微软,Google自研TPU配Gemini。现在,DeepSeek配华为昇腾,算第三对。
我想吐槽一下
过去几年AI圈有个怪现象。大家嘴上都喊"国产替代",但身体很诚实,训练用英伟达,推理用英伟达,部署还是用英伟达。
不是不想用国产芯片,是真跑不起来,或者跑起来性能拉胯。
寒武纪、摩尔线程这些国产GPU厂商,这些年没少努力,但生态建设总是差口气。模型厂商不愿意专门适配,芯片厂商又拿不到足够多的模型来调优,鸡生蛋蛋生鸡的问题卡了好几年。
这次DeepSeek V4破了这个局。
发布当天,除了华为,寒武纪也完成了Day 0适配,摩尔线程的S5000也跑通了。DeepSeek在模型架构层面就给多硬件平台留了口子,不是事后补丁,是设计之初就考虑到的。
但华为的适配是最深、最全的。从推理到训练,从云端API到边缘部署,全栈打通。华为云甚至直接上了MaaS平台,你不用自己部署模型,调个API就行。
以前是"国产芯片能不能跑大模型"的问题,现在变成了"怎么跑得更好"的问题。这是质的飞跃。
对我们有什么影响
短期可能感受不明显。你用的AI助手不会因为这个新闻突然变聪明。
但有几个变化已经在发生:
API价格降了。V4-Pro限时2.5折,缓存命中的输入价格低到0.25元/百万Token。这个价格,小公司也能玩得起了。
政务、金融、医疗这些敏感领域,终于有完全国产化的方案了。以前不是不想用国产,是真没有能打的组合。现在有了,DeepSeek的模型加华为的芯片,数据安全和供应链安全都能兜住。
下半年昇腾950批量上市后,价格还会再降。DeepSeek官方已经明示了。大模型的使用成本会进一步下探,更多应用场景会被激活。
说两句掏心窝的
我关注国产AI芯片好几年了。中间有过很多失望的时刻。每次看到"重大突破"的新闻,点进去一看,要么是实验室数据,要么是特定场景下的跑分,真正能用到生产环境的寥寥无几。
但这次不一样。
DeepSeek V4是真的能打的模型,华为昇腾是真的能扛的芯片,两者结合是真的能用的方案。
不是PPT,不是Demo,是已经上线、可以调用的API。
1.6万亿参数,跑在完全国产的芯片上,性能不输国际一线。
这句话我等了很久。它不只是一条科技新闻,它是一个信号:中国AI,开始真正走自己的路了。
数据来源:IT之家、DeepSeek官网、华为官方公告(2026年4月24日)
 微信
微信 支付宝
支付宝

